
redis基础

redis基础
mengnankkzhouredis数据类型
基础
String
redis中的数据是以键值对的形式存储的,然后存储是以二进制安全的形式进行存储
默认是不支持中文的,但连接的时候可以加上参数—raw,就是以原始的形式进行存储。这样就可以看到中文了
set:set key value 设置一个键值对
get:get key,返回的是值
1 | 127.0.0.1:6379> set name 你好 |
1 | 127.0.0.1:6379> get name |
del:del key,用来删除一个键
exists:exists key 用来看一个键是否存在
1 | 127.0.0.1:6379> exists name |
返回1表明存在
keys:key * 用来查看所有的键,支持通配符
1 | 127.0.0.1:6379> keys * |
flushall:flushall用来刷新所有的键
TTL:TTL key,用来查看一个键的过期时间
1 | 127.0.0.1:6379> ttl key |
返回-1表示没有过期时间
返回-2表示已经过期
expire:expire key time 设置一个键的过期时间
1 | 127.0.0.1:6379> expire name 99 |
setex:setex key time value,设置一个过期时间的键值
1 | 127.0.0.1:6379> setex age 99 88 |
setnx:setnx key value,只有当键不存在的时候才设置值
List
list是一个有序集合,可以重复、
list数据类型数据支持索引下标操作,只是性能较差
list数据类型的底层是双向链表
lpush:lpush Listname value,添加到头
rpush:rpush Listname value,添加到尾
lrange:lrange Listname start end,查看一个列表
这里index是从0开始的
1 | 127.0.0.1:6379> lpush list 88 |
lpop:lpop Listname,从头部弹出元素
rpop:rpop Listname,从尾部弹出元素
1 | 127.0.0.1:6379> lpop list |
也可以一次性删除多个元素,后面加上个数就可以了
llen: llen Listname,查看列表的长度
1 | 127.0.0.1:6379> llen list |
ltrim:ltrim name start end,只保留start-end的元素
1 | 127.0.0.1:6379> ltrim list 0 -1 |
set
没有顺序,不能重复
set是value为null的hash表
set命令可以进行运算交集,并集,差集等
sadd:sadd name value,添加元素
smembers:smembers name,查看元素
1 | 127.0.0.1:6379> sadd class 1 2 3 4 5 8 |
sismember:sismember name value,查看元素是否在set集合中
1 | 127.0.0.1:6379> sismember class 8 |
srem:srem name value,删除元素
1 | 127.0.0.1:6379> srem class 8 |
sortedset
有序集合,每个集合中的元素,都会关联一个浮点类型的分数
按照这个分数进行排序,从小到大
元素是唯一的,但分数是可以重复的
zset底层的存储结构包括ziplist或skiplist,在同时满足有序集合保存的元素数量小于128个和有序集合保存的所有元素的长度小于64字节的时候使用ziplist,其他时候使用skiplist。
zadd:zadd name score value,插入一个元素
zrange:zrange name start end withscore,查看集合中的元素
1 | 127.0.0.1:6379> zadd r 800 a 600 b 700 c |
1 | 127.0.0.1:6379> zrange r 0 -1 withscores |
zscore:zscore name value,查看该元素的分数
zrank:zrank name value,查看排名
1 | 127.0.0.1:6379> zrank r b |
zrevrank:zrevrank name value,查看排名,从大到小
1 | 127.0.0.1:6379> zrevrank r b |
zrem:zrem name value,删除集合中的元素
可以做成排行榜
hash
hset:hset name key value,设置键值对
hget name key ,获取值
hegt:hgetall name,获取全部的键值对
hdel:hdel name key,删除键值对
hexists:hexists name key,键值对是否存在
hkeys:hkeys name,获取所有键
hlen:hlen name 获取数量
1 | 127.0.0.1:6379> hset person name lihua age 100 |
发布订阅模式
subscribe:subscribe name,订阅频道
publish:publish name value,发布消息到name
1 | 127.0.0.1:6379> subscribe zhou |
1 | 127.0.0.1:6379> publish zhou 你好啊 |
消息无法持久化,无法记录历史消息
stream
xadd name id key value,添加一条消息,id可以使用*自动生成id
xlen name,查看消息的数量
xrange name - +,查看所有的消息
xdel name id,删除一条消息
xtrim name maxlen 0,删除所有消息
1 | 127.0.0.1:6379> xadd stram 1-0 man 1 |
xread count 2 block 1000 streams name 0,一次读取两条消息,没有消息阻塞1s,从0开始读取
0可以改成$符号,代表最新的消息
1 | 127.0.0.1:6379> xread count 2 block 1000 streams stram 0 |
xgruop create name gname id,创建一个消费者组,在创建一个之前没存在的组的时候,需要参数mkstream
xinfo groups name ,查看一个组的信息
1 | 127.0.0.1:6379> xgroup create redis group1 0 mkstream |
xgroup createconsumer name group consumer,创建一个消费者
1 | 127.0.0.1:6379> xgroup createconsumer redis group1 consumer1 |
xreadgroup group gname consumer count 2 block time streams name >,读取最新的消息
1 | 127.0.0.1:6379> xreadgroup group group1 consumer1 count 2 block 1000 streams redis > |
geospatial
geoadd name 经纬度 name,添加一个经纬度
geopos name name,获取一个经纬度
geodist name A B ,计算两个地方的距离,默认是米,加上km为千米
1 | 127.0.0.1:6379> geoadd city 116.41667 39.91668 beijing |
geosearch name frommember A byradius 800 KM ,搜索A,⚪800千米以内的地方
1 | 127.0.0.1:6379> geodist city beijing shanghai KM |
bitmap
bitmap 就是通过一个 bit 位来表示某个元素对应的值或者状态, 其中的 key 就是对应元素本身,实际上底层也是通过对字符串的操作来实现。bitmap 支持的最大位数是 232 位,使用 512M 内存就可以存储多达 42.9 亿的字节信息。
1 | SETBIT key offset value (offset位偏移量,从0开始) |
很适合用于「签到」这类只有两种取值的场景。比如按月存储,一个月最多 31 天,那么我们一个用于再某一个月的签到缓存二进制就是:
1 | 00000 00000 00000 00000 00000 00000 0 |
当某天签到将 0 改成 1 即可。
setbit name 第几位bit 1,第几位bit改为1
get bit name bitnumber,获取第几位bit的值
1 | 127.0.0.1:6379> SETBIT key1 7 1 |
bitcount name start end,统计start到end1的数量
1 | 127.0.0.1:6379> bitcount key1 0 8 |
BITFIELD key
[GET type offset]
[SET type offset value]
[INCRBY type offset increment]
[OVERFLOW WRAP | SAT | FAIL]
type:字段类型,比如 i8、u4,表示有符号/无符号整数,占几位
i8:8 位有符号整数(-128 到 127)u4:4 位无符号整数(0 到 15)
offset:字段偏移位(第几个 bit)
- 支持绝对偏移
0、5,或相对偏移(比如#0)
value / increment:要设置的值或增加的值
1 | 127.0.0.1:6379> bitfield key1 set u8 0 100 |
BITFIELD mykey INCRBY i5 0 1
把从第 0 位开始的 5 位有符号整数加 1
BITFIELD mykey OVERFLOW SAT INCRBY u4 0 10
如果加法结果超出 u4(无符号 4 位整数最大 15),则使用 “饱和” 模式(最大值就是 15)
WRAP(默认):溢出后从头开始(环绕)
SAT:饱和到最大或最小值
FAIL:溢出时返回 null,不更新
签到系统模拟
1 | # 一个用于在 2021 年 8 月第一个签到了 |
将一系列较小的数存在一个较大的位图中
bitfield key set u8 #1 100,将第1个位置设置成100
bitfield key get u8 #1,查看第一个位置的
1 | 127.0.0.1:6379> bitfield player:1 set u32 #1 100 |
hyperloglog
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。
什么是基数?比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8},基数(不重复元素个数)为5。 基数估计就是在误差可接受的范围内,快速计算基数。类似hashmap不能有重复的值
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身
HyperLogLog 算法是一种非常巧妙的近似统计海量去重元素数量的算法。它内部维护了 16384 个桶(bucket)来记录各自桶的元素数量。当一个元素到来时,它会散列到其中一个桶,以一定的概率影响这个桶的计数值。因为是概率算法,所以单个桶的计数值并不准确,但是将所有的桶计数值进行调合均值累加起来,结果就会非常接近真实的计数值。
HyperLogLog不存储输入元素
pfadd name element,插入元素到name
pfcount name 返回基数的估计
pfmerge name1 name2 合并
1 | 127.0.0.1:6379> pfadd cat 1 |
合并之后的name在前面
基数统计可以用作统计活跃ip,统计非重复的数据
redis事务
Redis 事务是 Redis 提供的一种 原子性操作,使得一系列命令可以作为一个整体执行,从而确保操作的一致性和可靠性。事务中的命令要么全部成功,要么全部失败,不会出现部分成功的情况。只有报错的语句不能执行。不能保证原子性和持久性。
Redis默认不开启事务
通过 MULTI 命令启动,进入事务模式,之后的所有命令都会被加入到事务队列中,但不会立即执行。
然后输入命令….
输入完成之后
通过 EXEC 命令提交执行,Redis 会按顺序依次执行在事务队列中的所有命令。
事务可以通过 DISCARD 命令放弃,丢弃事务队列中的所有命令。
which监视一个或多个键。如果监视的键在事务执行前被其他客户端修改,事务会被中止。
UNWATCH取消监视
1 | 127.0.0.1:6379> bitfield player:1 get u32 #1 |
这样的话,事务被终止了,体现了他的原子性
1 | 127.0.0.1:6379> multi |
执行成功的事务
redis持久化
因为redis是存储在内存之中的,所以关机后数据会消息
这个时候就需要redis持久化来保存数据
RDB
在指定时间间隔能对数据进行快照存储,类似 MySQL 的 dump 备份文件。
rdb是默认的持久化机制,是将当前进程数据以生成快照的方式保存到硬盘的过程。
1 | vim /usr/local/redis/conf/redis.conf |
在配置文件中修改
1 | # 放行 IP 访问限制 |
在 redis.conf 文件末尾加上:
1 | 900 秒内如果超过 1 个key改动,则发起快照保存 |
这就备份了一个快照,快照是默认的持久化方式。这种方式就是将内存中数据以快照的放入写入二进制文件中,默认的文件名为 dump.rdb,可以通过配置设置自动做快照持久化的方式。
产生快照的情况有以下几种:
- 手动
bgsave执行(不会阻塞,后台一点点备份) - 执行BGSAVE命令时要执行fork操作创建子进程。
- 手动
save执行(会阻塞,不接受客户端命令,备份完了才放开)。 - 根据配置文件自动执行。
- 客户端发送
shutdown,系统会先执行 save 命令阻塞客户端,然后关闭服务器。 - 当有主从架构时,从服务器向主服务器发送
sync命令来执行复制时,主服务器会执行bgsave操作。
也可以手动执行save,但是这个过程中redis是阻塞的
所以可以创建一个子进程,边处理边备份 bgsave
AOF
记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据(MySQL 的 binlog)。
也就是每次处理完请求命令后都会将此命令追加到 .aof 文件的末尾。而 RDB 是压缩成二进制等时机开子进程去干这件事。
在配置文件中通过配置 redis.conf 进行启动,默认是关闭的
1 | 默认 appendonly 为 no |
Redis 中提供了 3 种 AOF 同步策略:
- 每秒同步(默认,每秒调用一次
fsync,这种模式性能并不是很糟糕)。everysce - 每修改同步(会极大削弱 Redis 的性能,因为这种模式下每次
write后都会调用fsync)。 always - 不主动同步(由操作系统自动调度刷盘,Linux 是 30s 一次,性能是最好的)。 no
1 | 每秒钟同步一次,默认 |
重写
随着运行时间的增长,执行的命令越来越多,会导致 AOF 文件越来越大,当 AOF 文件过大时,Redis 会执行重写机制来压缩 AOF 文件。这个压缩和上面提到的 RDB 文件的算法压缩不同,重写机制主要是将文件中无效的命令去除。比如:
- 同一个 key 的值,只保留最后一次写入。
- 已删除或者已过期数据相关命令会被去除。这样就避免了 aof 文件过大而实际内存数据小的问题(如频繁修改数据时,命令很多,实际数据很少)
触发条件:
手动执行
bgrewriteaof触发AOF重写。在
redis.conf文件中配置重写的条件,如:1
2
3
4当文件小于64M时不进行重写
auto-aof-rewrite-min-size 64MB
当文件比上次重写后的文件大 100% 时进行重写
auto-aof-rewrite-min-percenrage 100
常用配置:
1 | # fysnc 持久化策略 |
redis主从复制
主从复制是一个为redis主节点,很多个从节点。
一个主节点对应多个从节点,一个从节点只能对应一个主节点

1 | role |
查看当前节点的角色,默认是主节点
通过info Server命令,可以查看节点的服务器运行ID(runid)
复制偏移量(offset)代表主节点向从节点传递的字节数
复制积压缓冲区的作用是备份主节点最近发送给从节点的数据
配置过程
分别在三台机器上运行以下命令:
1 | # 创建配置目录 |
三台机器都创建一份新的 redis.conf
1 | vim /usr/local/redis/conf/redis.conf |
写入以下内容
master节点:
1 | 放行 IP 访问限制 |
slave节点:
1 | 放行 IP 访问限制 |
其中
1 | slaveof 172.16.58.200 6379 |
这个是最重要的,指定主节点的ip和端口号
info replication
查看当前集群的情况
然后slave从节点是跟主节点是一致的,一般来说主节点负责写,从节点负责读
slaveof no one命令可以用于断开主从复制关系
从节点断开主从复制关系后,不会删除数据,只是不会再更新新的数据
从节点服务器中的masterhost和masterport字段,分别存储主节点的ip和port信息
如果从节点中设置了masterauth选项,则从节点需要向主节点进行身份验证;没有设置该选项,则不需要验证
复制原理
log日志分析过程
1 | 主节点已就绪,等待从节点连接 |
复制分类
全量复制一般是 Slave 刚开始连接 Master 后做的数据同步过程。
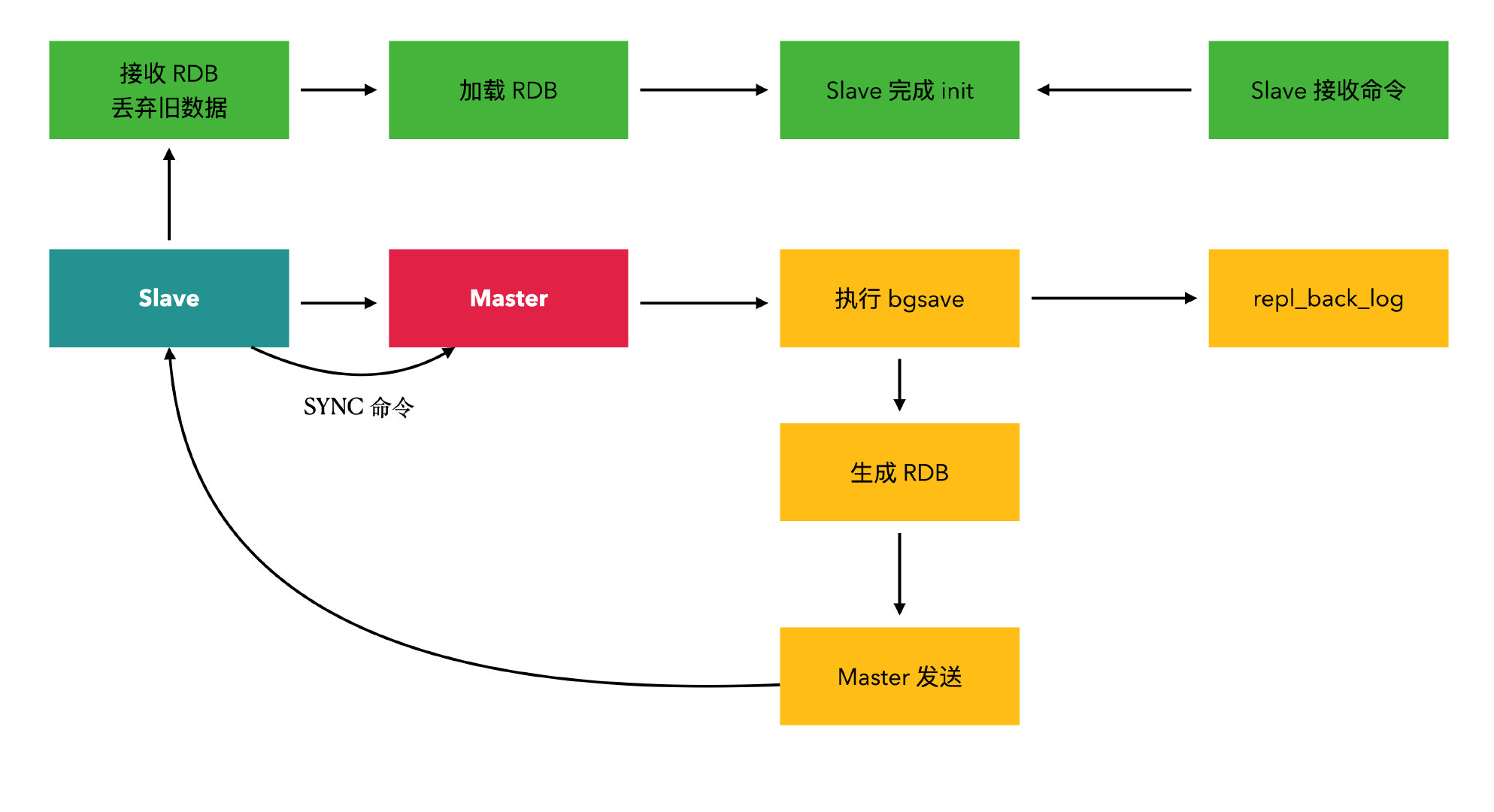
如果从节点保存的runid与主节点现在的runid不同,说明从节点在断线前同步的Redis节点并不是当前的主节点,只能进行全量复制
增量复制
增量复制是 Slave 初始后开始正常工作时 Master 发生写操作时同步到 Slave 的过程。
从节点与主节点发生短暂失联后重新连接,也会根据
master_repl_offset和second_repl_offset进行增量复制。- 复制过程就是 Master 每执行一个写命令就会去 Slave 发送相同的写命令,Slave 接收并执行收到的写命令。
情况处理
主从复制异步性:
- 主从复制对于 Master 是非阻塞的,当 Slave 在进行主从复制同步过程中,Master 仍然可以处理外界的访问请求。
- 主从复制对于 Slave 是非阻塞的,当 Slave 在进行蛀虫复制过程中也可以接收外界的查询请求,只不过这时候 Slave 可能返回以前的老数据。
过期的key处理:
- Slave 不会让 key 过期,而是等待 Master 让 key 过期。当 Master 让 key 过期时,它会合成一个 del 命令并传输到所有的 Slave。
加速复制:
- 默认情况下,Master 节点接收 SYNC 命令后执行 bgsave 操作,将数据先保存到磁盘,如果磁盘性能差,那么写入磁盘会消耗大量性能,因为在 Redis 2.8.18 后进行改进,可以设置无需写入磁盘直接发送 RDB 快照给 Slave,加速复制。
- 修改配置:
repli-diskless-sync yes(默认是 no)
主从数据一致性:
主从网络延时
- 主多从少:部分重同步
- 主少从多:全量复制
数据延迟
编写外部程序监听主从节点的复制偏移量,延迟较大时发出报警或通知客户端,切换到主节点或其他节点。
设置 Slave 节点 slave-serve-stale-data 为 no,除 INFO 和 SLAVEOF 命令之外的任何请求都会返回一个错误 SYNC with master in progress。
脏数据
原因:
- Redis 删除机制导致(惰性、定时、主动删除等)。
- 从节点可写导致。
解决:
- 忽略
- 选择性强制读主,从节点间接变成了备份服务器(只针对某个业务)。
- 从节点只读,规避从节点写入脏数据。一般来说应该是用这个
- 目前 Redis 读取数据之前会检查 key 过期时间来决定是否返回数据
数据安全
关闭 Master 持久化会提升性能,同时会带来复制的安全性问题。
- 开启 Master 持久化。
- 在 Docker 或者脚本中设置 Master 不自动重启。
缺陷:
故障恢复无法自动化
写操作无法负载均衡
存储能力受到单机的限制
哨兵模式
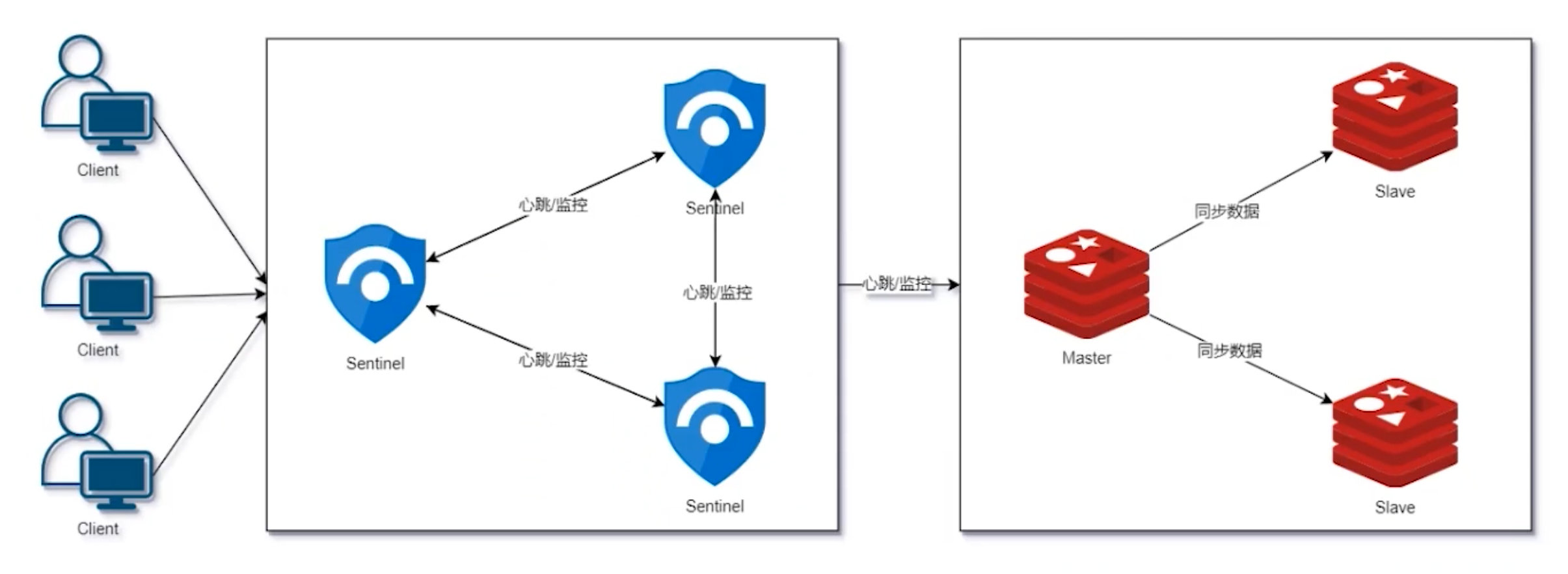
Redis Sentinel 是分布式系统中监控 Redis 主从服务器,并提供主服务器下线时自动故障转移功能的模式,其中四个特性为:
- 监控(monitoring)
- 提醒(notification)
- 自动故障迁移(Automatic failover)
- 配置提供者(Configuration provider)
注意事项:
- 默认端口:26379
- 至少 3 个 Sentinel 实例
- 运行 Sentinel 必须制定配置文件
- 独立的虚拟机或物理机中运行
- 可配置 Sentinel 允许丢失有限的写入
- 客户端要支持 Sentinel
- 经常在测试环境中测试
- 在 Docker、端口映射或网络地址转换的环境中配置要格外小心
配置过程
首先要运行前要运行着主从模式
分别创建 sentinel.conf:
1 | vim /usr/local/redis/conf/sentinel.conf |
sentinel.conf:
1 | 放行所有 IP |
最重要的是这
1 | sentinel monitor mymaster 172.16.58.200 6379 2 |
2代表有两个哨兵才能替换主节点,这就是仲裁机制
quorum 机制
sentinel down-after-milliseconds对主节点、从节点和哨兵节点的主观下线判定都有效
sentinel failover-timeout是用来判断其几个子阶段的超时
sentinel master mymaster用于获取监控的主节点mymaster的详细信息
info sentinel用于获取监控的所有主节点的基本信息
sentinel sentinels mymaster用于获取监控的主节点mymaster的哨兵节点的详细信息
sentinel failover mymaster用于强制对mymaster执行故障转移
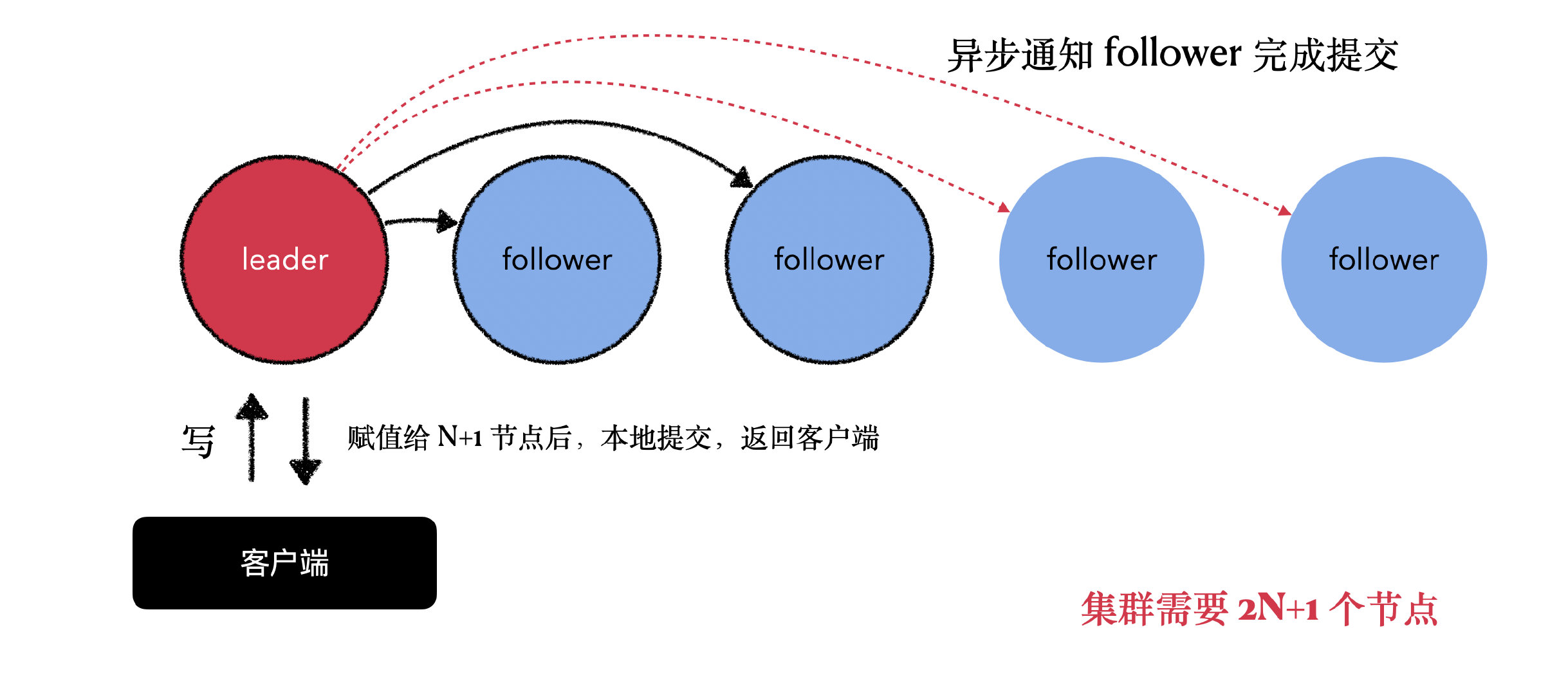
抽屉原理:
- 一个群体 9 个人,有一个秘密,告诉给该群体中的任意 5 个人,那么随便挑选 5 个人,至少有 1 个人知道秘密。
quorum 机制:
quorum 机制是抽屉原理的一种实际应用,经常用于分布式系统,是一种少数服从多数的思想。
quorum 机制在分布式共识算法当中经常是用来减轻写的压力(相应的读压力会增大),如:

启动哨兵节点
1 | redis-sentinel sentinel.conf |
原理分析
查看日志:
1 | # 加载 sentinel.conf 配置 |
定时任务:
- 每 1 秒每个 Sentinel 对其他 Sentinel 和 Redis 节点执行
ping操作(监控) - 每 2 秒每个 Sentinel 通过 Master 节点的 channel 交换信息(Publish/Subscribe)
- 每 10 秒每个 Sentinel 会对 Master 和 Slave 执行
INFO命令
redis集群
redis集群的作用是:
实现故障的自动转移
提高响应能力
突破了单机内存大小限制
在哨兵模式基础上解决了单机内存大小限制问题
节点收到PUBLISH命令后,会先执行该命令,然后向集群广播这一消息,
面试问题
1.redis是单线程的原因
避免线程切换和竞争产生的消耗
避免同步机制的开销
实现简单,底层数据结构的设计无需考虑线程安全
然后在Redis6.0版本引入了多线程的目的是解决Redis在网络 I/O 上的性能瓶颈
2.redis授权的利用方法包括以下哪种
1.利用crontab反弹shell
直接向靶机的Crontab写入任务计划,反弹shell回来
2.写入webshell
当自己的redis权限不高时,可以向web里写入webshell,但需要对方有web服务且有写入权限
3.写ssh-keygen公钥然后使用私钥登陆
(1)redis对外开放,且是未授权访问状态
(2)redis服务ssh对外开放,可以通过key登入








